
UTD Hackathon 总结
前言
这是前段时间参加UTD Hackathon的总结。
这是在TAMU的同学邀请一起去往往的,我主要负责了爬虫这个部分。所以这里主要讲讲我的工作。其他我不了解的部分也就不多说了,不要布鼓雷门了。
这个项目的出发点就是我们希望开发一个类似12306抢票助手的工具来预约驾照考试。主要是我同学提出的需求,原来美帝和我们买火车票一样,需要先预约驾照考试。但是这儿存在一个什么矛盾呢,TAMU所在的college town人特别多,就和春运火车票一样需要不断刷预约。
据同学说有中国人就开发了这个软件,对外销售。当然这个行为我们等会再讨论,首先指望我们这种喜欢自己动手的人花钱买这个是不切实际的。所以这次同学联合他的两个学弟我们一起开发这个项目。
我们的项目在这儿,全部开源。当然因为时间有限,所以我们有的代码写得非常粗糙,欢迎斧正。
HackUTD : Find Available Driving Test Appointment
原 理
首先如果你希望自动化一个功能,那么你一定要能够手动实现这个功能。如果你没有很高的AI设计,计算机是很难自己自动实现某些功能的。
首先计算机的预约过程是打开Texas Department of Public Safety ,如下图所示,然后选择服务,一般都是小车预约。当然这里我们已经选择好了所在城市2571 North Earl Rudder Freeway Bryan, TX 77803,也就是TAMU所在的college town。
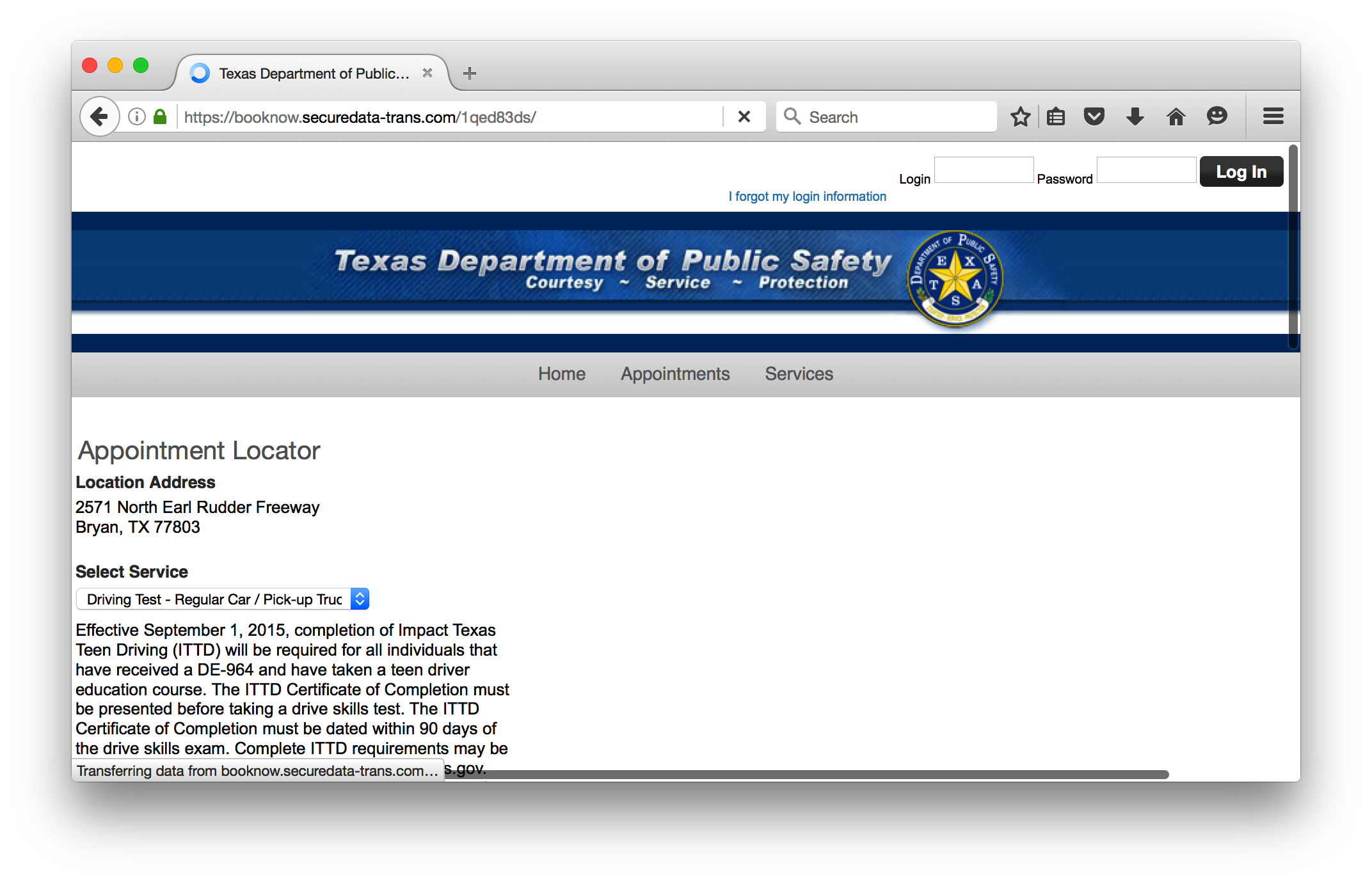
然后就会出现一个时间表,这个表中灰色的是已经预约满了的,白色的是可以预约的点击即可。值得注意的是不能预约当天,同时不能预约超过90天的。
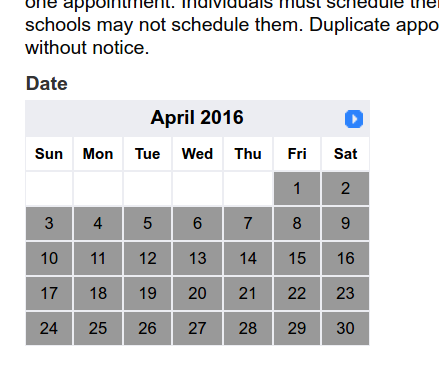
这里需要注意的,这个网页是在我们点击之后才生成的,同时表格月份日期的那栏有向左和向右的箭头。这两个箭头如果打开分别对应了两个Javascript脚本从而实现动态更新部分网页的功能。
如何实现对于Javascript脚本的爬取
对于静态的HTML页面我们可以使用Beautiful Soup进行页面解析从而得到我们需要的页面内容,但是如何处理Ajax,Javascript?
通常来说有两个思路:
- 你直接得到相应的脚本,然后对于脚本返回的信息(一般是XML或者JSON)做解析
- 直接模拟浏览器,因为浏览器对于用户呈现的数据一定是静态HTML的。
我选择第二个方法,使用selenium 的 webdriver 功能来实现解析。这样,通过模拟浏览器的点击等行为我们可以方便的进行交互。
然后得到了需要的静态HTML之后只要进行相应的解析处理即可。主要来说所有需要的信息是日期和是不是可以注册,所以只要针对这个日期标的数据做解析即可,而 Texas Department of Public Safety 的这个网页写得非常规范,所有日期分成四个种类,calendar-closed 这是指当天,calendar-notavailable 这是已经过去的日期和超过 90 天的日期,calendar-fullday 这是虽然在90天内但是注册满了的日期,calendar-available 顾名思义就是可以注册的日期。所以爬取信息也很简单直接通过 class 得到这几个属性即可。最后得到的结果放到数据库中,给其他程序使用。
程序整体思路
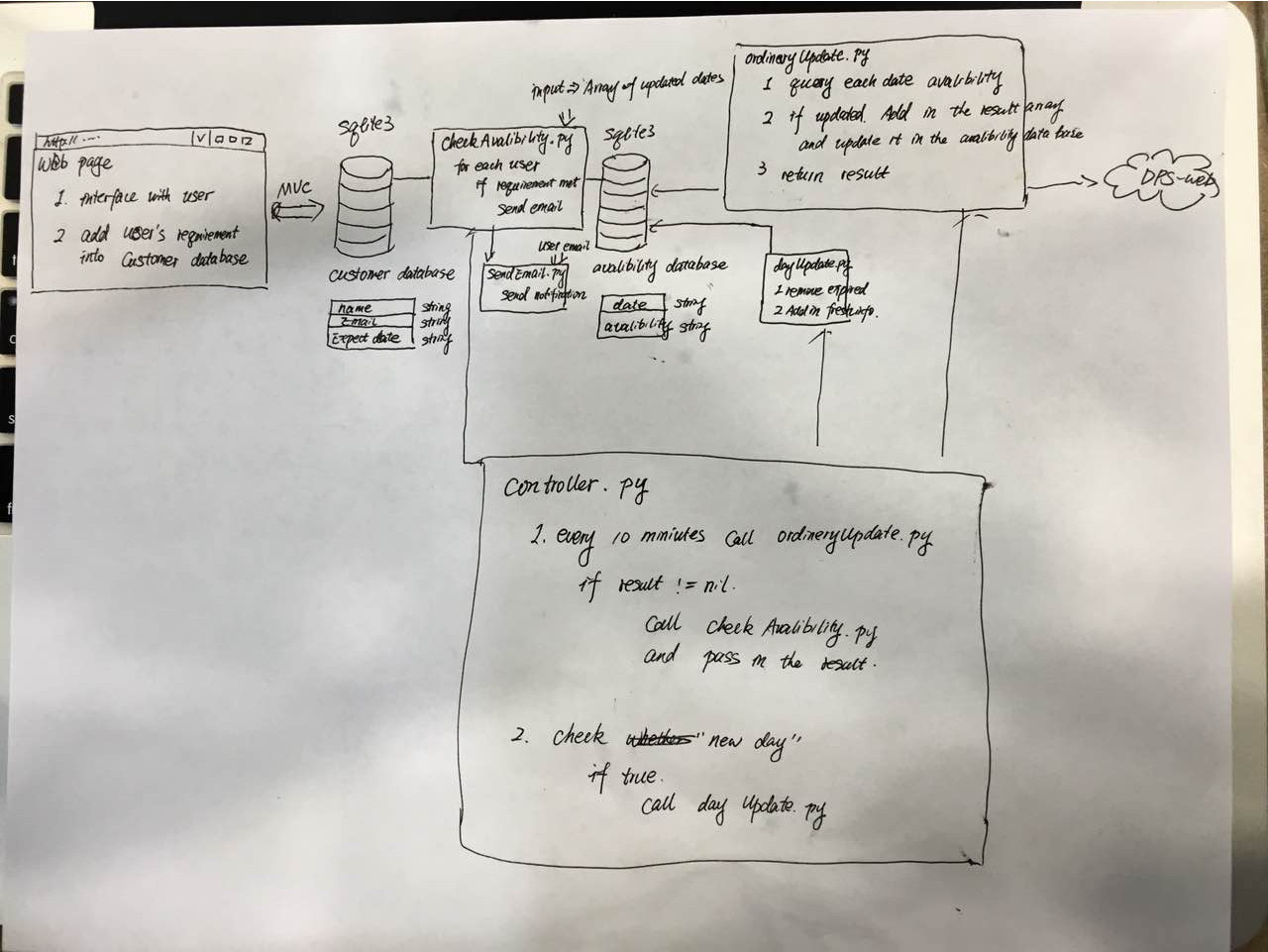
上图就是我们的整体设计框架,主要的部分是首先前端基于 ruby on rails 。UI效果如下:
后端实现一个每过10 分钟扫描一遍预约信息网站的更新脚本。然后如果检测到不同且该日期属于注册用户的指定日期,那么调用发送邮件程序给该用户发送可以预约的邮件,提醒用户赶快上网预约。
总结
这个任务其实比较简单,但是能够连贯起来还是非常不错的。当然对于一般用户而言,我们不需要暴露这么多细节。事实上做成一个网站就可以了,让用户使用的主要是前端部分。
当然要是方便的话,实现 iOS 或者 Andriod 客户端就更好了。
这个留待以后解决。
update 10 mins的Python代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
"""
Created on Sun Mar 27 06:42:50 2016
@author: iphyer
output :
return value
1 means sth changed
0 nothing changed
"""
# import needed package
from selenium import webdriver # web action
from pyvirtualdisplay import Display
from datetime import date
import BeautifulSoup as bs
import sqlite3
import pickle
# function setup
def htmltableGetinfomation(websource,data_page):
"""
get information from html source
input : html source code
output : dict of data and availibility
"""
month2num = { 'January' : 1, 'February': 2,'March' : 3,'April': 4,'May': 5,'June': 6,'July' : 7,'August': 8, 'September': 9, 'October': 10, 'November' : 11, 'December': 12}
soup = bs.BeautifulSoup(websource)
table = soup.find(lambda tag: tag.name=='table' and tag.has_key('id') and tag['id']=="calendar")
temp = table.findAll('span')
Mon, Year = temp[0].string.split()
# insert starting day calendar-closed
Mon = month2num.get(Mon)
Mon = int(Mon)
Year = int(Year)
days_closed = table.findAll(lambda tag: tag.name=='td' and tag.has_key('class') and tag['class'] == 'calendar-closed')
for i in days_closed:
Day = int(i.text)
date_temp = date(Year,Mon,Day).strftime("%m/%d/%Y")
data_page[date_temp] = 0
# insert following day calendar-fullday
days_full = table.findAll(lambda tag: tag.name=='td' and tag.has_key('class') and tag['class'] == 'calendar-fullday')
for i in days_full:
Day = int(i.text)
date_temp = date(Year,Mon,Day).strftime("%m/%d/%Y")
data_page[date_temp] = 0
# insert following day calendar-available
days_available = table.findAll(lambda tag: tag.name=='td' and tag.has_key('class') and tag['class'] == 'calendar-available')
for i in days_available:
Day = int(i.text)
date_temp = date(Year,Mon,Day).strftime("%m/%d/%Y")
data_page[date_temp] = 1
#print "==========================================="
#print data_page
return data_page
def creat_sqlite(Allowed_Days_Dict):
"""
creat sqlite of 90 allowed time with their availability
input : Allowed_Days_Dict = {date : availability}
"""
#connecting database and creating table availability
conn = sqlite3.connect("development.sqlite3")
cursor = conn.cursor()
cursor.execute("""DROP TABLE IF EXISTS availability""")
cursor.execute("""CREATE TABLE IF NOT EXISTS availability
(date text,av int) """)
dictlist = []
for key, value in Allowed_Days_Dict.iteritems():
temp = [key,value]
dictlist.append(temp)
cursor.executemany("INSERT INTO availability VALUES (?,?)" ,dictlist)
conn.commit()
cursor.close()
conn.close()
def sqlreading():
pkl_file = open('myfile.pkl', 'rb')
Allowed_Days_Dict_old = pickle.load(pkl_file)
pkl_file.close()
return Allowed_Days_Dict_old
def dictDiff(dictA,dictB):
for key,val in dictA.iteritems():
if ( val != dictB[key] ):
return 1
def renewSQL(changed,Allowed_Days_Dict):
if ( changed ):
creat_sqlite(Allowed_Days_Dict)
output = open('myfile.pkl', 'wb')
pickle.dump(Allowed_Days_Dict, output)
output.close()
if __name__ == "__main__":
"""
method description :
1.get four month available and unavailable days and then return as a dict
2.dict to sqlite
"""
#Assign URL for search
#Appointment Locator
# Location Address
# 2571 North Earl Rudder Freeway
# Bryan, TX 77803
URL = 'https://booknow.securedata-trans.com/1qed83ds/'
#four_months for result record
Allowed_Days_Dict = dict()
# get webpage information
display = Display(visible=0, size=(800, 600))
display.start()
# now Firefox will run in a virtual display.
# you will not see the browser.
browser = webdriver.Firefox()
browser.implicitly_wait(5)
browser.get('https://booknow.securedata-trans.com/1qed83ds/')
browser.find_element_by_xpath("//select[@name='service_id']/option[text()='Driving Test - Regular Car / Pick-up Truck']").click()
source = browser.page_source
Allowed_Days_Dict = htmltableGetinfomation(source,Allowed_Days_Dict)
#get another 3 pages information
for i in range(1,4):
browser.execute_script("javascript:dosubmit1('no', 'yes', 'log_in')")
source = browser.page_source
Allowed_Days_Dict = htmltableGetinfomation(source,Allowed_Days_Dict)
#print "==========================================="
#print Allowed_Days_Dict
browser.close()
#reading in the old date dict
Allowed_Days_Dict_old = sqlreading()
changed = 0
changed = dictDiff( Allowed_Days_Dict_old, Allowed_Days_Dict)
renewSQL(changed,Allowed_Days_Dict)
print "================update_10min Done==========================="
exit(changed)