
PythonDownloadBook
下载书籍
好久没有更新这个技术blog了,今天终于可以写一个新的内容了。 主要是关于一本书的《西藏生死书》,这本书总是在图书馆借不到,所以自己写程序去下载。
程序思路
其实很简单就是读入网页,然后用BeautifulSoup解析网页内容,本来以为会有好多内容的,结果最后发现用一个语法就可以解决了。 主要是这个网页比较干净,几乎没有什么其他的东西。 当然程序的实现还是需要很多的其他环境的,比如这个网站是gbn2312编码的,但是内中还夹杂了其他的编码,所以python一开始老是报错。 最后借助了很多的其他手段解决了。比如Linux环境。
程序
# -*- coding: utf-8 -*-
"""
Created on Thu Mar 21 15:38:23 2013
@author: Aimzest
"""
import urllib2
from bs4 import BeautifulSoup
fh=open('content.txt','a+')
#参数设定
urllinkmain="http://www.oklink.net/00/0325/sss/"
urllinkadd=".htm"
#下载程序
fh.write(u"西藏生死书 \n")
for n in range(1,27):
temp=str(n)
temp=temp.zfill(3)
bookfilelink=urllinkmain+temp+urllinkadd
#解析网页
request = urllib2.Request(bookfilelink)
request.add_header('User-agent', 'Mozilla/5.0 (Linux i686)')
response = urllib2.urlopen(request)
soup=BeautifulSoup(response,from_encoding="gb18030")
content=soup.get_text()
#输出章节标题和内容
fh.write(content)
fh.close()
print 'Done'
这是最后的程序版本。
当然还要手动去掉那些多出来的东西,主要是
- 返回上页
- 一个css的残留项目。估计是里面有中文所以去不掉
就是这个字符串
#page {position:absolute; z-index:0; left:0px; top:0px}
.swy1 {font: 12pt/16pt "宋体"}
.swy2 {font: 9pt/12pt "宋体"}
我一直没想明白怎么去掉。但是可以手动使用查找替换所以其实也很简单了。
或者下载到本地以后,再读入content重新修改估计都是可以的。
总结
主要是三点
字符串的迭代
这里我需要产生,001,002,003的字符串。其实很简单的方法就可以了:
for n in range(1,27):
temp=str(n)
temp=temp.zfill(3)
python的zfill真是强大。
urllib的访问限制
urllib是尊重roobtxts里面的限制的。所以比较好的方法是加上一个修饰:
比较完整表达是:
urllib2 respects robots.txt.
Many sites block the default User-Agent.
Try adding a new User-Agent, by creating Request objects & using them as arguments for urlopen
request = urllib2.Request(bookfilelink)
request.add_header('User-agent', 'Mozilla/5.0 (Linux i686)')
response = urllib2.urlopen(request)
很好的解析网页命令
这个命令绝对实用啊
content=soup.get_text()
直接就可以得到需要的网页内容了。
StackOverFlow是神迹
我在写的时候有一个问题,在stackoverflow上提问,结果一下就有5个人回应,真实神迹啊! 比百度知道靠谱多了。
赞!
效果
最后的效果如下,导入kindle慢慢欣赏了。
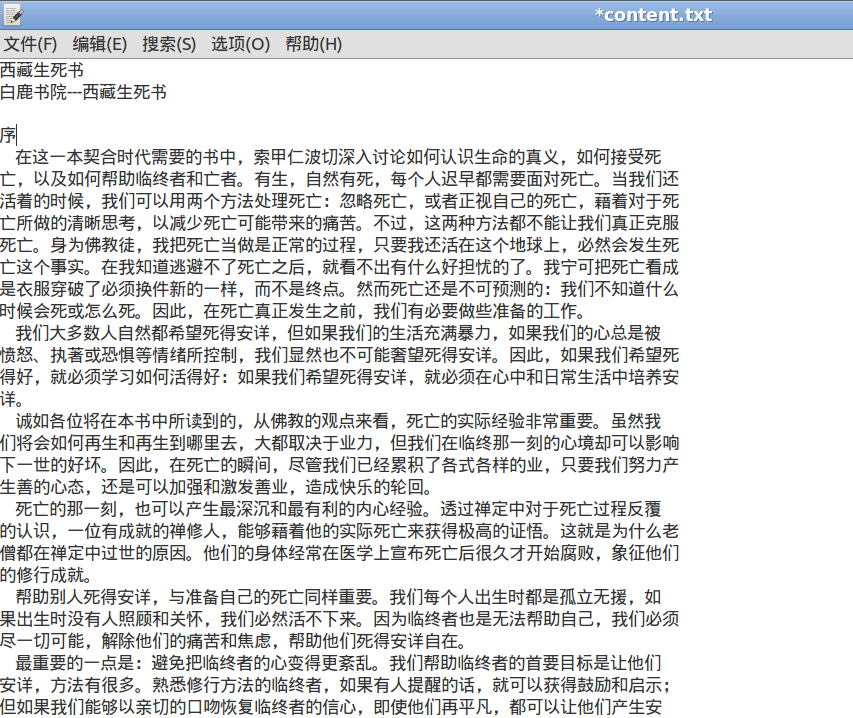
Written on March 23, 2013