
Python编程12——Python作葛底斯堡演讲的词频统计图
前言
这篇的主要程序部分和“Python编程9——Python分析葛底斯堡演讲的词频统计”完全一样,就是多引入了两个库,同时多做了一个做图函数。
程序
#getttsburg addresss analysis
#count words, unique words, common wrods
#here we want to do word frequence analysis of the addresss
import string
import numpy
import pylab
def processLine(line,wcDict):
#cut the whitespace before and after everyline
#sitll use strip method to seperate different words
wordlist=line.strip().split()
for word in wordlist:
if word !="--":
word=word.lower()
word=word.strip()
word=word.strip(string.punctuation)
addword(word,wcDict)
def addword(w,wcDict):
if w in wcDict:
wcDict[w]+=1
else:
wcDict[w]=1
def prettyPrint(wcDict):
valkeyList=[]
for key,val in wcDict.items():
valkeyList.append((val,key))
valkeyList.sort(reverse=True)
print '%-10s%10s'%('word','count')
print '-'*21
for val,key in valkeyList:
if (len(key) >3) and (val>2) :
print '%-12s %3d'%(key,val)
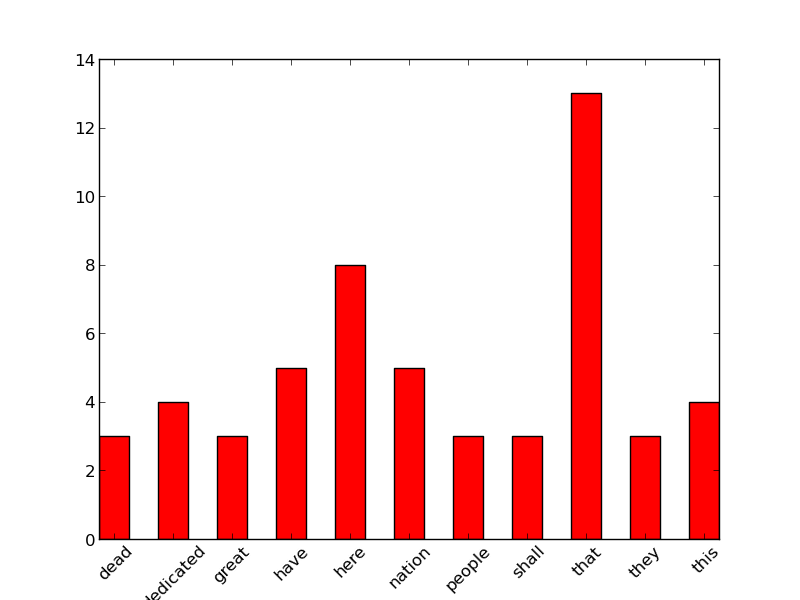
def barGraph(wcDict):
wordlist=[]
for key,val in wcDict.items():
if val>2 and len(key)>3:
wordlist.append((key,val))
wordlist.sort()
keylist=[key for key,val in wordlist]
vallist=[val for key,val in wordlist]
barwidth=0.5
xVal=numpy.arange(len(keylist))
pylab.xticks(xVal+barwidth/2.0,keylist,rotation=45)
pylab.bar(xVal,vallist,width=barwidth,color='y')
pylab.show()
#main programe
wcDict={}
fObj=open("gettysburg.txt",'r')
for line in fObj:
processLine(line,wcDict)
print 'Length of the wcDict is:', len(wcDict)
prettyPrint(wcDict)
barGraph(wcDict)
Written on January 13, 2013