
Python编程10——Python做葛底斯堡演讲的词频统计
前言
这里继续接着前面的工作做下去。
这里主要不单单是统计出葛底斯堡演讲的单词分别打印出来,还希望可以作进一步的分析。比如,这篇演讲使用频率最多的词汇是哪些。 这里主要的特点是使用了Python的字典数据结构,生成字典来计算词频。
主要的算法是三步:
- 打开文件,每次只处理文件中的一行数据
- 查找字典的键值。对于每一个新的词语添加到字典中记为一个新的key,val设为1;否则对于已有的key,val+=1
- 对于字典输出,按照键值的从大到小排列
相应的程序中的三个函数如下:
processline→addword→prettyPrint
其中重点的内容如下:
- 使用string包中的string.punctuation去除所有单词后面的标点。
- addword使用in查看是否单词在字典之中
- 排序的时候必须遍历字典,使用items方法。同时对于字典将key 和val调换,以使用sort方法排序。
程序
#getttsburg addresss analysis
#count words, unique words, common wrods
#here we want to do word frequence analysis of the addresss
import string
def processLine(line,wcDict):
#cut the whitespace before and after everyline
#sitll use strip method to seperate different words
wordlist=line.strip().split()
for word in wordlist:
if word !="--":
word=word.lower()
word=word.strip()
word=word.strip(string.punctuation)
addword(word,wcDict)
def addword(w,wcDict):
if w in wcDict:
wcDict[w]+=1
else:
wcDict[w]=1
def prettyPrint(wcDict):
valkeyList=[]
for key,val in wcDict.items():
valkeyList.append((val,key))
valkeyList.sort(reverse=True)
print '%-10s%10s'%('word','count')
print '-'*21
for val,key in valkeyList:
if (len(key) >3) and (val>2) :
print '%-12s %3d'%(key,val)
#main programe
wcDict={}
fObj=open("gettysburg.txt",'r')
for line in fObj:
processLine(line,wcDict)
print 'Length of the wcDict is:', len(wcDict)
prettyPrint(wcDict)
程序中值得一说的是去掉无意义词汇的过程
if (len(key) >3) and (val>2) :
程序的难点还是在prettyPrint()这个函数的编写的,确实是输出的格式上非常让人需要调整。 当然经验也比较重要。
这一行代码去掉长度小于2同时出现次数太低的词汇,然后得到了结果如下:
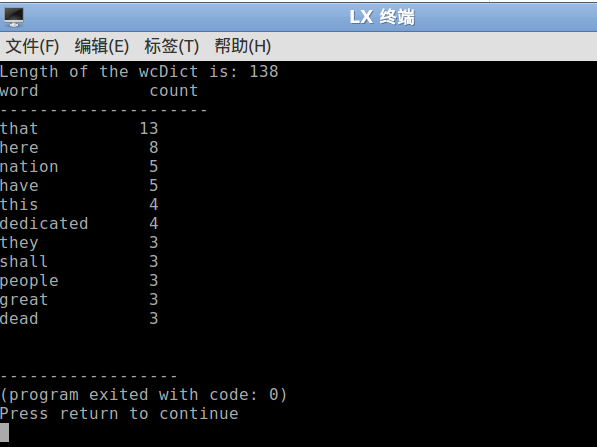
Written on January 13, 2013