
运用R做数据分析
前言
现在看来我还是很早就看到了大数据的潜力,居然 2012 年我就开始了 R 语言的学习。。。
1.什么是R?
在R的官方教程里是这么给R下注解的:一个数据分析和图形显示的程序设计环境(A system for data analysis and visualization which is built based on S language.)。当然这个解释还是比较难解。笼统的讲,R是一个可以和SPSS,SAS这些商用软件对抗的统计软件。我第一次接触到R就是在2011年暑假,南京大学和Hopkins大学联合举办生物统计的暑期课程。在第一节课上,助教就展示了关于R的用法和思路。虽然那是一个暑假课程但Hopkins大学的老师一样很深入的讲了R的使用。印象最深刻的是关于用R来做基因组序列分析的实验部分。从那以后我对R就很喜欢,甚至很多的实验都是借助R来完成的。
R 其实是Rick Becker,John Chambers 和Allan Wilks 开发的 S 语言的一种实现,这三个人都在贝尔实验室工作,他们合作开发了S语言来进行统计的运算,并且开发了商用的SPLUS。关于R的历史,大家可以google。
简而言之,R是一个开放、开源、共享的软件系统,借助它你可以实现几乎所有的统计和计算工作,甚至有人用R来做模拟和分析。R有着开源软件共有的特点,拓展包多,借助各种拓展包,你可以实现从生物上的基因序列分析到商业上网站访问的聚类分析。同时任何人都可以自由的使用、分享R而不需要担心版权的问题,这大大促进了R的发展。正如Hopkins的老师说的:“Not all people can afford the cost of using SPSS or SAS even though they are easy to start with.” 当然在中国这点并不是特别重要,但是可怕的是如果你和外国同学交流或者你有机会出国的时候却发现没法和大家交流因为你使用的是盗版软件而别人很多在使用开源的软件,你却都没有听说过。更可怕的是当我们环顾图书馆的藏书时候发现好多都是在讲怎么用SPSS和SAS的,老师上课也是这么教同学的,这样的循环是可怕的。因为大家永远也接触不到开源软件的魅力与开源的精神。
同时,或许在医学,商业领域SPSS们可以和R相匹敌,但是在生物统计或者大规模数据分析上R可以说是一骑绝尘,鲜有敌手。因为这些需要高度专门性的领域,R这样可以编程,自由修改的软件系统绝对是适用的。
2.安装R
2.1windows环境
在Google直接输入R,第一个搜索结果就是R project的官网,选择一个镜像地址访问,下载Precompiled Binary Distributions 中的软件。如果是Windows 用户,可以点击Windows (95 and later),进入base,选择rwxxxx.exe下载,很快就可以下载好,然后安装一般的windows下的安装程序安装,除了语言一般选择默认的配置就可以使用R了。
然后可以下载RStudio这个软件,它可以把R的界面改装成和Matlab类似的界面,工作空间,内存空间,结果和软件包展示区,相当的方便。
2.2Linux环境
在ubuntu的环境下主要是使用RKWard这样的类似编辑环境,当然在Linux下也是可以用Rstudio的只是要去官网上下载deb的包。也可以直接显示数据同时进行操作,当然也可以使用命令行的模式运行R。
3.R的语法
3.1数据结构
首先注意,R是大小写敏感的。其次在R中基本的数据结构由
- 数值型(numeric): 1,1.2,3.1415926
- 复数型(complex): 1+2i
- 字符型(character): ‘A’/”hello world!”
- 逻辑型(logical): TRUE/FALSE
R中基本的数据对象为下列五类:
- 向量(vector)
- 矩阵(matrix)
- 列表(list)
- 数据框(data frame)
- 函数(function)
3.2基本类型的操作
赋值操作为:对于任何一个变量名X1使用下列命令
X1<-c(......)
其中c(……)代表一个数据列。比如:
X1<-c(1,2,3,4)
就是将数组(1,2,3,4)f赋值给X1.
当然,如果我们从R的数据类型上入手的话,此时我们是生成一个向量。下面演示一个矩阵的生成方法,这个时候很死板的方法是把矩阵一行一行的输入,中间用“,”隔开即可。当然也可以使用比较高级的方法,比如:
y1<-matrix(c(1,2,3,4,5,6,7,8,9),nrow=3,ncol=3,byrow=FALSE)
y2<-matrix(1:9,nrow=3,ncol=3,byrow=FALSE)
可以看到两种方法产生的结果y1 和 y2 完全一样。
下面介绍列表。列表最大的特点就是可以实现不同类型的数据可以用同一个变量表示,从而构成不同数据类型的一个变量集合。
比如:
x<-list(gender=c('F','M'),grade=c(98,100,90),undergrad=TRUE)
上面的命令是建立一个list的列表,可以看到各个对象的属性并不相同,而且长度也不强行要求一致。
你还可以用下列三个命令输入对于gender进行操作,如:x$gender和x[[1]]
最后的一个是要求R告诉x这个变量名有多少变量,如: names(x)
下面介绍数据框,数据框是和列表相同的一类数据结构,都可以处理不同类型的数据,但是数据框严格要求各个组成部分的长度相同。比如:
y<-data.frame(gender=c('F','M'),grade=c(98,100),undergrad=c(FALSE,TRUE))
上面的操作,我特意选择了和list相同的内容R直接报错,而在R的内存中可以看到正确的y的数据分布。
希望大家可以知道各种不同的数据结构在内存中具体的逻辑表示,因为不同的数据结构直接决定你在设计不同的数据处理时候的方法。
3.3数据文件的读写操作
既然是对于统计数据进行操作,所以肯定离不开具体的对于数据文件的操作。一般而言最最方便的数据读写形式就是文本文件,当然很多的时候我们使用的excel的格式,这个时候建议大家把excel文件存成cvs的格式,这样也可以方便进行操作。当然如果你下载了读取excel文件的专门包的话,也是可以操作的。
主要的读写操作命令是下面两个:read.table() 适合 读写ASCII 文件,read.csv()适合读写Excel/CSV文件。要注意的是read.table()并不适合读写太多太大的矩阵结构,这个时候可以用scan()命令代替。
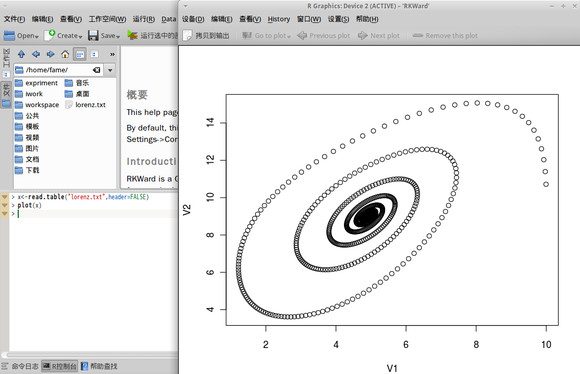
比如我有一个已经存储好的txt数据文件,名字叫做lorenz.txt,下面就有这个文件做一个数据读写的展示。
则命令是:
x<-read.table("lorenz.txt",header=FALSE)
注意:
这里我省略了设置你的工作目录的工作,这是因为,我把这个文件放在我的 home 文件夹下,如果不是的话,运行下列命令:getwd()得到你的工作目录,一般在 Linux 中这个是默认设置在 home 文件夹下的,当然如果你在 Windows 下可以用如下命令:setwd("C:/Users/XXXX") 里面填上你喜欢的路径即可。
这个文件是关于洛沦兹方程的,所以我加了一个 plot() 命令展示它的结果:
当然如果是excel的格式使用下面的命令:
y<-read.csv('lorenz.csv', header=TRUE)
当然,另外一个命令的方向就是从R向文件中写数据可以使用如下命令:
write.table(x,'lorenz.txt',col.names=FALSE, sep='\t')
3.4一个使用R的例子
下面结合一个实际实验中例子给大家展示一下用R可以做的物理实验数据处理。曾近在一次实验中我们需要拟合一条直线,这是在单摆的振动中,我们测量它的不同振幅从而希望可以得到单摆的衰减系数。这个实验设计中包含如何从视频文件中读出数据,然后进行数据处理,这里面包含像素坐标和实际坐标的转换,我们假设全部得到这些数据了。我下一步需要关注数据的拟合操作。
首先我们输入数据文件,命令如下:
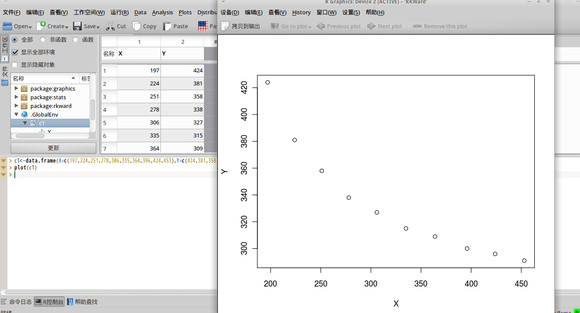
c1<-data.frame(X=c(197,224,251,278,306,335,364,396,424,453),Y=c(424,381,358,338,327,315,309,300,296,291)
这里使用数据框从而保证下一步不需要担心数据输入的时候有缺失或者不全。
下面让我们简单估计一下数据的分布与图像,从而得到下一步的行动方法。加上一个 plot() 命令即可, plot(c1)。
图像如下:
下面的任务就是对于这个图像的拟合。
从原理上分析我们已经知道了这个图像的衰减规律符合如下的函数形式:Y=a+bexp(-cX),所以所有的工作就是求解这个拟合的系数。我们使用如下的命令:
nls.sol<-nls(Y~a+b*exp(-c*X),data=c1,start=list(b=215.8,a=40.18,c=0.01478))
nls.sum<-summary(nls.sol);nls.sum
R给出如下的输出结果:
Formula: Y ~ a + b * exp(-c * X)
Parameters:
Estimate Std. Error t value Pr(>|t|)
b 1.347e+03 1.829e+02 7.366 0.000154 ***
a 2.870e+02 2.734e+00 104.965 1.88e-12 ***
c 1.170e-02 7.230e-04 16.182 8.37e-07 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 2.62 on 7 degrees of freedom
Number of iterations to convergence: 8
Achieved convergence tolerance: 1.686e-06
如果你还是没有办法从上面的残差分析中看出拟合的好坏的话,我们使用如下命令拟合所有的曲线,得到具体的拟合的图像结果。
xfit<-seq(180,480,len=2000)
yfit<-predict(nls.sol,data.frame(X=xfit))
plot(c1$X,c1$Y);lines(xfit,yfit)
结果如下:
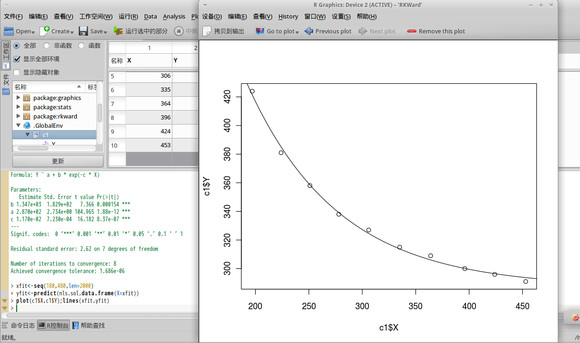
可以看到拟合的结果相当好,最后的结果是:Y=287.0+1347exp(-0.0117X) 。
3.5进一步深入提高
上面的内容充其量只能算是一个导引,大家如果愿意深入的学习R的操作有很多的材料可以学习。第一个就是An Introduction to R by Venables and Smith,这个也是R的官方简介,也是全世界学习R的入手手册。几乎可以说初级中级使用者所有的东西这本书都具备。当然,它的缺点就是例子太过简单,同时因为简单所以很多例子缺少实战效果。推荐薛毅的《统计建模与R软件 》这个是相当不错的书。前面复习了一下统计的基本知识后面几乎都是结合例子进行的讲解。当然如果你是为了快速查找某些命令可以看看《R语言使用笔记》 这是从薛毅的《统计建模与R软件 》中精简出来的命令集合。当然网上也有很多的材料,最著名的就是人大统计之都 COS论坛 确实是很有效果的。当然如果英文够好,推荐直接去CRAN,CRAN是R的官方所有资料的归档的地方,全称是The Comprehensive R Archive Network,也是相当权威的地方。
4.总结
这篇文章主要是关于R,这个著名而有效的统计和数据处理系统。其实R最有效的地方是有很多专门化的软件包,相信所有做过是生物统计的人都不会忘记在Bioconductor这个软件包的陪伴下度过的日日夜夜。希望你也可以欣赏到R的伟大魅力